
Over the past month I’ve been exploring mechanistic interpretability – a field dedicated to understanding the internal workings of machine learning models.
I set out to find patterns in LLMs, but the real value I got from this project was finding a pattern in myself. I hope anyone reading this who discovers that pattern in themselves too, realizes that not only are they not alone, but they are powerful and capable.
How did we get here?
The AISF Course
Ever since I read Superintelligence, I’ve been equally fascinated by both the possibilities and problems that come along with the quest for artificial general intelligence (human-grade AI). So I was both excited and nervous to be accepted into BlueDot’s AI Safety Fundamentals: Alignment course. Excited, for hopefully obvious reasons, but nervous because my machine learning background was minimal. I wondered how many others there would be like me.
This type of situation has been a pattern in my life. I started physics classes early in my high school career so I could take more of them, yet worried how I would measure up to the older students with higher level math experience. I took a job in technical support after college because I became fascinated by how the internet worked, but worried how I would fit in having next to no computer science experience and consistently realizing I was the only woman in the room at work. I followed that line of interest into a software engineering role and, once again, struggled with the idea that I didn’t have a CS degree or a passionate history of playing with Linux machines and writing Java during summer vacations like my peers.
Now here I was, again, putting myself into a situation where I felt excited and interested, but also underprepared and out of place.
The Project
The final month of the course was dedicated to an individual project. After learning about mechanistic interpretability, I knew I wanted my project to be in this space. Mech interp seeks to look inside the black box that is a machine learning model and understand exactly how it makes sense of data we give it to generate an output – and that’s cool af. I wanted my project to reflect the amazement I felt, but with only a basic software engineering background, having only read the articles from the coursework with the barest understanding of what was actually technically happening in them, and no idea what a transformer was . . . I worried about what I could actually accomplish.
Throughout the project, we were encouraged to read less, do more – to dive in. While this is not something I do often, I wanted the full experience of the course as intended, so instead of finding some long tutorial that I’d never actually finish about how transformers work, I embraced the directive and committed myself to finding a do-able project with an actual output.
When I came across this list of 200 open problems to explore in the field of mechanistic interpretability, I started to feel hopeful. They are laid out by category and – most importantly, for me – by difficulty. I found the most beginner-est of beginner problems and set my sights on that. It had a simple, exploratory goal – “search for patterns in neuroscope and see if they hold up.”
Okay, what is neuroscope?
Quick LLM Refresher
When text is input to an LLM, it’s broken down into different segments for the model to work with. These segments of text are called tokens. For example, the text “Hi, I am Courtney” might be broken down by a model into this list of tokens [“Hi”, “,”, “I”, “am”, “Courtney”].
LLMs are neural networks, so when data is passed into them, the neurons making up the network learn to activate based on different aspects of that data. Basically, each neuron is going to really like some tokens and not care about others. The neurons each activate on different parts of the text, but they connect with one another to turn all of those different activations into a (hopefully!) meaningful output.
Okay, back to neuroscope
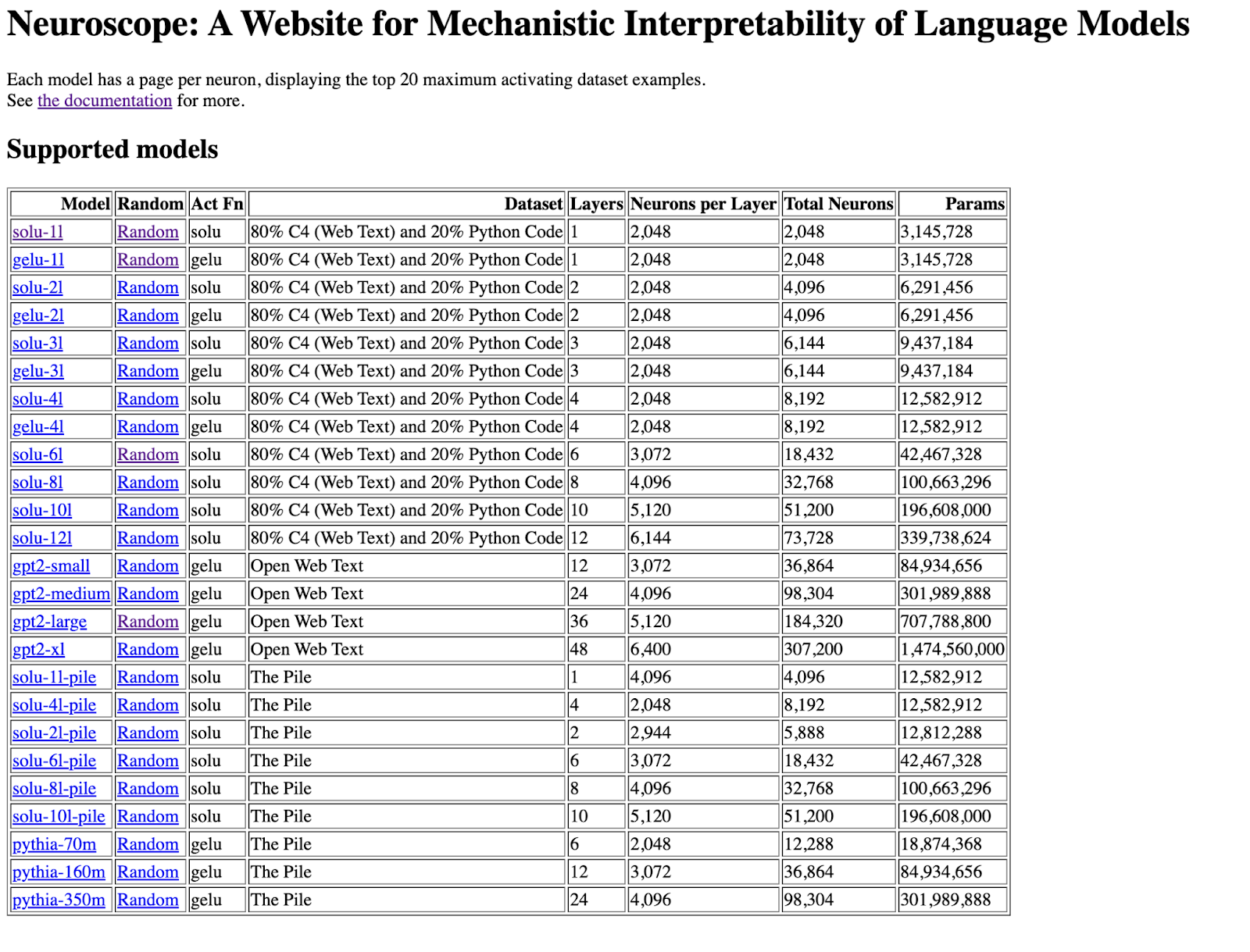
Neuroscope is a website created by mechanistic interpretability researcher, Neel Nanda, which catalogs every neuron in a given LLM. Each neuron has its own page on the site, which shows the twenty segments of text that most activated that specific neuron. Within those segments of text, the tokens that most strongly activated the neuron are highlighted in increasing shades of blue. The more intense the color, the more “excited” that neuron felt about the word.

The website leverages a python library called TransformerLens to do this. It’s called TransformerLens because it looks at transformers. Naturally, the question then arises, what is a transformer? All I can say for now is that it’s the architecture used to create LLMs. Other than that most basic of understanding, I still don’t actually know.
The Plan
My project plan was to see if I could detect commonalities in the texts that most strongly activated a given neuron. I wanted to find neurons that seemed to be highlighting the same types of numbers or words in a pattern that could suggest some feature that the neuron had been trained to represent within the model.
I wanted to know how hard this actually was to do and how many iterations through random neurons it would take to find something. I expected to spend the entire project searching for an elusive single pattern. Instead, I found what might be several. The following is a breakdown of the questions I asked, the hypotheses I formed, and the answers I found.
Phase 1: Exploring neuroscope
How hard was it to find a pattern?
This honestly took less time than I expected. I wish I had logged how many neurons I clicked through, but all I can say is that it didn’t take more than a few hours to find nine potential patterns.
I selected the first model in the supported models list (because why not?), solu-1l. Then I clicked to view a “random” neuron in that model over and over again, skimming through the texts on each page and looking for human-readable indications of patterns. Specifically, this meant looking for repetition (ex. successive numbers were always highlighted) or a common theme (ex. all the texts were recipes).
How would I know if I truly found a feature?
The next step was verifying whether or not the pattern I thought I found held up to scrutiny. To do this, I decided to pull from the arguments for curve detector neurons in visual models to craft a test. I found and created examples that were not in the initial set of texts from neuroscope, but which matched the pattern I thought I was seeing. I also created texts that specifically did not match the pattern to ensure these texts did not generate strong activations.
Then, I used the interactive version of neuroscope — a notebook that can do what the neuroscope website does, but on demand. In the notebook, you can specify your model and your neuron, and then pass in any input text that you want to see how much the neuron “likes” it (based on how intensely the words are highlighted).
If I shared the details of all nine patterns I tested, this might become unreadable, so I’ll just share two – one that seemed promising in light of my hypothesis and one that did not. For each one, I first validated that the interactive neuroscope was working as expected by loading the appropriate model and neuron (under “Extracting Model Activations”), then running it on one of the strongly activating texts listed on the neuroscope website the outputs were the same.
Solu-1l, layer 0, neuron 260

Hypothesis
Activates strongly for “I”, “you”, and “we” in review or comment text.
Developing test texts
From Amazon’s homepage, I selected the first review from each of the first ten products shown. I compared this with the same set of texts, but with the pronouns stripped.
Examples
| Matches the pattern | Does not match the pattern |
| I disliked nothing I loved it, perfect size | Disliked nothing loved it, perfect size |
| I recently purchased the Women’s Casual Long Sleeve Button Down Loose Striped Cotton Maxi Shirt Dress, and I absolutely love it! The material is soft and comfortable, and the loose fit is perfect for all-day wear. The striped pattern adds a nice touch of style, and the buttons down the front make it easy to put on and take off. And best of all, it has pockets. Overall, highly recommend! | Recently purchased the Women’s Casual Long Sleeve Button Down Loose Striped Cotton Maxi Shirt Dress, and absolutely love it! The material is soft and comfortable, and the loose fit is perfect for all-day wear. The striped pattern adds a nice touch of style, and the buttons down the front make it easy to put on and take off. And best of all, it has pockets. Overall, highly recommend! |
Results
Out of ten sets of test texts, not a single one highlighted the pronouns of the review text as expected. There was no visual distinction betwen the test texts that matched the pattern and those that did not.
Solu-1l, layer 0, neuron 737

Hypothesis
Activates strongly for numbered or lettered lists when written as “x)”.
Developing test texts
I used a combination of personally written lists and lists found from recipes that matched the pattern. I compared them to lists that deviated from the pattern.
Examples
| Matches the pattern | Does not match the pattern |
| a) Aurora b) Penumbra c) Luna | Aurora Penumbra Luna |
| “WHY YOU WILL LOVE THIS RECIPE! 1) Creamy and Flavorful: 2) Easy and Quick: 3) Versatile and Adaptable: 4) Nourishing and Satisfying: 5) Fall Comfort Food: “ | “WHY YOU WILL LOVE THIS RECIPE! 1. Creamy and Flavorful: 2. Easy and Quick: 3. Versatile and Adaptable: 4. Nourishing and Satisfying: 5. Fall Comfort Food: “ |
Results
Out of six sets of test texts, every single one highlighted the lists as expected!
Phase 2: I guess I’ll write some code now?
Phase 1 was originally intended to be the entirety of the project. I did not expect to be able to understand and use the tools so quickly. So what to do with the remaining project time?
I could have continued to search for patterns, but I wondered what else I could do. Again, though, I felt intimidated. Could I learn enough to do anything in such a short timespan (or ever, thought my anxious brain)? I remembered the excitement that I felt when initially learning about mechanistic interpretability and how freeing it felt to embark on a project focused around exploration rather than production. I wanted to continue in that mindset.
As I pondered my situation, the universality claim (that features represented in one model can be found represented in other models too) came to mind and a silly thought arose. Would it be possible to write a gigantic loop that iterated over every single neuron in an LLM and check for one of the features I thought I found in phase 1? How long would that take to run? Would my laptop meet a fiery end?
That sounded fun.
What I wrote
TransformerLens lets us look at a given text as a list of tokens. My plan was to programmatically get the indices of the most activating tokens for the neurons that I had tested in phase 1 and iterate through every single neuron in another model to see if any of those neurons activated strongly on the same indices.
You can see the code here.
Results
This code takes around 90 minutes to run, but it did in fact complete! There is a nest of three for loops in there, which is always fun, but rarely practical (unless you really need that time to make a sandwich, which I did).
The code runs, but I have yet to find neurons representing the same features in another model. And I think this could be why —
| Model name | Text | Total tokens | Token break down |
| solu-1l | 8) singled out 9) personality | 8 | 0 => ‘ 8’ 1 => ‘)’ 2 => ‘ sing’ 3 => ‘led’ 4 => ‘ out’ 5 => ‘ 9’ 6 => ‘)’ 7 => ‘ personality’ |
| gpt2-small | 8) singled out 9) personality | 7 | 0 => ‘ 8’ 1 => ‘)’ 2 => ‘ singled’ 3 => ‘ out’ 4 => ‘ 9’ 5 => ‘)’ 6 => ‘ personality’ |
The same piece of text may not be tokenized the same way for each model. This means when looking for activations in the new model at the indices of the most activating tokens from my initial model (where the feature was discovered), I’m looking at totally different pieces of text. To highlight this issue with the example above, if the number “9” was very strongly activating for the neuron in solu-1l (my initial model), that would be index 5 in the list of tokens for that model. If I looked for neurons in gpt2-small that activated at index 5 of the list of tokens it generated from the same exact text, it would be looking for neurons that were strongly activated by a closing parenthese.
Conclusion
Why did any of this matter?
My technical achievements throughout this project have been minimal at best – a couple of neuron activation patterns were proofed amateurly, a draft PR was created for TransformerLens with some failing tests (that I didn’t touch?) because I like to leave code better than I found it, and a half-finished proof-of-concept for automating universality testing was created. But I did complete the goal I set out to accomplish — search for patterns in neuroscope and see if they hold up — and more.
Story Time
Reflecting on this project, I’m reminded of the time I decided to get a Red Hat certification. I wanted to know more about the internet and servers, but instead of diving in, I thought I would skill up first. Once I had a linux administrator’s certification, surely then I would be very knowledgeable and capable and able to get a job in this space. The problem with this approach, though, was that I had never had a job in this space. Most of the lessons and tasks from the book I was using to study either made no sense or seemed completely pointless.
I still do not have that certification. For a time, I internalized the experience as a failure in me to be able to understand and perform that kind of work. But after spending a year as a tech support agent, I started to get it.
The Story Is Relevant – I Promise
I have a pattern of doing this – of trying to insulate myself from challenge and failure by learning “the right way” and only taking action when I’m “prepared.” Like studying for a test. And yet, the times I’ve been most successful in life (outside of formal schooling) have been when I’ve gotten myself in slightly over my head and rose to meet the challenge. The times when I stopped trying to be perfect and let life happen. The times when I figured out what was important or how something worked by participating in it.
The real purpose behind me writing this post is to encourage other SWEs, other women, and anyone else who might worry that they aren’t smart or skilled enough to do things in mech interp, or more broadly within AI Safety, or even more broadly in life.
It’s okay to dip your toes in. It’s okay to not read every instruction manual and GitHub ReadMe and forum post before developing ideas and trying stuff. It’s okay to put yourself in a position where you’ll be pushed out of your comfort zone. It is scary and it is hard and you probably won’t be the smartest person in the room. You may, in fact, be the dumbest person in the room. But that doesn’t mean that you can’t do it or that you don’t belong there.
Other stuff I learned
- Unsurprisingly a library all about transformers is difficult to go very deep with when you don’t know what a transformer is. To really understand the code and do more with it, I need a stronger understanding of how transformers work.
- For as small a field as mech interp is, it’s shockingly accessible, mostly because of Neel Nanda.
- Little tiny mistakes have always stumped me the most. I typed “solu-11” instead of “solu-1l” into the interactive neuroscope notebook and spent at least an hour trying to understand why the model wasn’t being found. I forgot to switch the layer number in the code a few times when swapping between models and spent at least an hour trying to understand why I was getting a bad index. This is a twofold learning:
- As software engineers, it’s critical to raise error messages that are as clear as possible. This ensures we spend our time on the big problems rather than the silly ones.
- In my first foray with programming, I spent an entire afternoon trying to figure out how to type the “big x” in html . . . you know >< . . . as in something like <div><\div> . . . yeah. It was incredibly discouraging. But I’ve made enough of these tiny, silly mistakes now to know that a) documentation really needs to treat us like we’re five and b) a long walk and a good rubber ducky community are invaluable tools for a programmer.
- Hacking something together that’s not great, but still manages to get the job done is often something I find fun. I should do that more.
Mech Interp Stuff To Explore Next
- Are patterns harder or easier to detect in models with more layers?
- Is there a more efficient way to look for evidence of universality if I understand transformers better? What about using numpy or scipy to compare histograms of activations?
- What kind of fun stuff can we explore with circuits and circuitvis integration?
- How can we better help SWEs get involved in this space?
Hey! I just wanted to thank you for writing this piece. I recently started the AISF course and I’ve been struggling to actually do things with mech interp for the past few months. It is genuinely daunting the amount of mathematical intuition and complexity that goes into understanding how these models work. Your piece inspired me to start way smaller and mess around with things. I just finished messing around with neuroscope to find if neurons activate for the same concepts across languages. It is super cool to finally be doing experimentation that I sort of understand and your article really pushed me towards that. Thanks!
Hi! Thank you so much for sharing that! I’m glad to hear that this was helpful to you. It means a lot to realize you’re not alone (at least, for me anyway). And I’d love to follow along with your experimentation if you end up sharing any of it.
Good article. Most importantly, fun to read.
Thanks!! I’m glad you enjoyed it